查找结构
如果给定一个序列,你将如何在这个序列中查找一个给定元素 target,当找到时返回该元素的迭代器,否则返回末尾迭代器。首先排除时间复杂度 \(\mathcal{O}(N)\) 的朴素算法,这不是本文的重点。
二分查找
二分法 (Dichotomy) 是一种思想,将一个整体事物分割成两部分,这两部分必须是互补事件,即所有事物必须属于双方中的一方且互斥。如此我们就可以在 \(\mathcal{O}(1)\) 的时间内将问题大小减半。
二分查找 (binary search),又称折半查找,这是一种可以在 \(\mathcal{O}(\log_{}{N})\) 时间复杂度下完成查找的算法。二分查找要求序列必须是有序的,才能正确执行:将序列划分为两部分,如果中间值大于 target,意味着这之后的值都大于 target,需要继续向前找;如果中间值小于 target,意味着这之前的所有值都小于 target,需要继续向后找。
AVL 树
上一篇介绍树时分析了 BST 中为什么很容易发生不平衡现象。在极端情况下,只有一个 leaf 的树,在查找元素时其时间复杂度退化为 \(\mathcal{O}(N)\) 。
为了防止 BST 退化为链表,必须保证其可以维持树的平衡,一次需要有一个 平衡条件
(balanced condition)。如果每个结点都要求其左右子树具有相同的高度,显然是不可能的,因为这样实在是太难了。在 1962 年,由苏联计算机科学家 G.M.Adelson-Velsky 和
Evgenii Landis 在其论文 An algorithm for the organization of information 中公开了数据结构 AVL (Adelson-Velsky and Landis) 树,这是计算机科学中 最早被发现的
自平衡二叉树。
AVL 的平衡因子
AVL 树将子树的高度限制在差为 1,即一个结点,如果其左子树与由子树的高度差 \(|D_{h}| \leq 1\) ,则认为这棵树是平衡的。因此带有平衡因子 \(-1\) 、 \(0\) 或 \(1\) 的结点被认为是平衡的,而 \(-2\) 或 \(2\) 的平衡因子被认为是需要调整的。平衡因子可以直接存储于结点之中,也可以利用存储在结点中的子树高度计算得出。

简单地计算,一棵 AVL 树的高度最多为 \(1.44 \log_{}{(N + 2)} - 1.328\) ,实际上的高度只比 \(\log_{}{N}\) 稍微多一些。一棵高度为 \(h\) 的 AVL 树,其最少结点数 \(S(h) = S(h - 1) + S(h - 2) + 1\) ,\(S(0)=1, S(1) = 2\) 。而 AVL 的所有操作均可以在 \(\mathcal{O}(\log_{}{N})\) 复杂度下完成。
AVL 的插入操作
在进行插入操作时,和普通的 BST 类似,但是不一样的是需要更新路径上所有结点的平衡信息,并插入完成后有可能破坏 AVL 的特性。如果特性被破坏后,需要恢复平衡才能算插入结束。实际上,总可以通过简单的操作进行修正,这种操作被称为 旋转 (rotation)。
将必须重新平衡的结点叫作 \(\alpha\) ,由于任意结点最多有两个孩子,因此高度不平衡时, \(\alpha\) 点的两棵子树的高度差 2。这种不平衡可能出现在下面 4 中情况中:
- 对 \(\alpha\) 的左孩子的左子树进行插入
- 对 \(\alpha\) 的左孩子的右子树进行插入
- 对 \(\alpha\) 的右孩子的左子树进行插入
- 对 \(\alpha\) 的右孩子的右子树进行插入
情况 1 和 4 关于结点 \(\alpha\) 镜像对称,情况 2 和 3 关于结点 \(\alpha\) 镜像对称。因此从逻辑上来讲,我们只需要考虑两种情况,而编程时需要考虑上面介绍到的所有 4 种情况。
单旋转
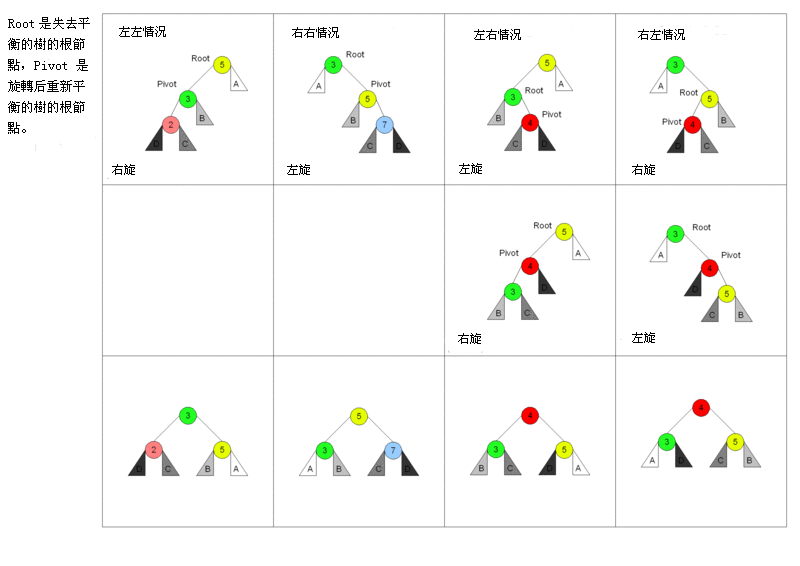
情况 1 是插入发生在「外边」的情形,我们称之为 一字形 (zig-zig),可以用 单旋转 (single rotation) 解决。假设结点 \(n\) 不满足 AVL 平衡性质,因为其左子树比右子树深 2 层,可以对其进行单旋转修正。修正的过程是:将左子树的根 \(l\) 向上移动一层,而将 \(n\) 向下移动一层, \(n\) 作为 \(l\) 的孩子出现在树中。下图展示了插入后出现不平衡的结点 (红色) 、如何旋转、多余子树如何处理以及子树的层数 (蓝字)。

对应的情况 4 也是 zig-zig,只需要旋转的方向与操作相镜像即可处理。
双旋转
对于情况 2 、 3 来说,插入在「树内」从而导致 AVL 树无效,这种情况被称为 之字形 (zig-zag),而子树太深通过 single rotation 无法让树平衡,解决这种内部的情形需要 * 双旋转* (double rotation) 解决。

对应的情况 3 也是 zig-zag,只需要旋转的方向与操作相镜像即可处理。
对 AVL 树插入的总结
可以发现,无论单旋转与双旋转,它都由两个最基本的操作组成:将结点进行左旋 (left rotation) 或右旋 (right rotation),并将多余的一棵子树挂载到下降结点上。Wikipedia 用以下这幅图概括了 4 种情况。
// 左旋
void rotate_left(Node* node) {
Node* child = node->right;
node->right = child->left;
if (child->left != nullptr) {
child->left->parent = node;
}
child->parent = node->parent;
child->left = node;
node->parent = child;
return child;
}
// 右旋
void rotate_right(Node* node) {
Node* child = node->left;
node->left = child->right;
if (child->right != nullptr) {
child->right->parent = node;
}
child->parent = node->parent;
child->right = node;
node->parent = child;
return child;
}在进行编程时,可以首先定义左右旋这两种基本操作,在根据情况判断如何组合。对于编程细节,远比理论多得多,编写正确的 loop 算法相对于 recursion 并不是一件容易的事,因此更多的会使用 recursion 进行实现。
还有一个重要问题是如何高效的对高度信息进行存储,可以采用平衡因子作为存储而不是一个 int 类型的高度,或者更近一步,利用 2 bit 存储平衡因子 (毕竟只有 3 个状态)。如果你希望将其隐藏到指针中,也是个不错的选择。存储平衡因子将得到些许速度优势,但丧失了简明性,如果你使用隐藏于指针的方法,更加剧的这一问题,不过好消息是你能为此剩下不少内存空间。最后,以 Wikipedia 上一副构建 AVL 树的动图作为本小节的结束吧。

AVL 的移除操作
AVL 树的移除与 BST 相当,同样地,移除操作可能会破坏 AVL 特性,因此我们在移除元素后,同样需要对树进行平衡才能算操作完成。
伸展树
或许你没有听过这种数据结构,但是它确实存在且就在这里。 伸展树 (splay tree) 是一种相对简单的数据结构,它保证从空树开始任意连续 M 次对树的操作最多花费 \(\mathcal{O}(M \log_{}{N})\) 的时间。这种保证并不排除单次花费 \(\mathcal{O}(N)\) 时间的可能,并且也不保证每次操作的最坏情况都是 \(\mathcal{O}(\log_{}{N})\) 的,不过好在实际上是一样的。当 M 次操作的序列总的最坏情况花费 \(\mathcal{O}(Mf(N))\) 时间,我们就说它的 摊还 (amortized) 运行时间为 \(\mathcal{O}(f(N))\) 的。因此 splay tree 的每次操作的摊还时间复杂度为 \(\mathcal{O}(\log_{}{N})\) 。
当然 splay tree 有着一个事实基础:对于 BST 来说,每次操作最坏情形花费 \(\mathcal{O}(N)\) 并非不好,只要它相对不常发生就行。为了保证 amortized,splay tree 进行一个结点访问就会发生移动操作,它要经过一系列旋转操作被推到 root 上。但是当这个结点过深时,重新将这棵树构造为平衡树可能会花费比旋转更少的时间。
实际上,从 splay tree 中也可以看出局部性思想,当一个结点被访问时,它与其附近的结点可能会被频繁的访问,而远端的结点可能很难被访问到。当抖动发生时,splay tree 将会面临非常巨大的开销,因为它总是需要调整较深层的结点。
简单的旋转
在实现 splay tree 时,访问一个结点并将其推向 root 时,最简单的方法就是 单旋转
,即该结点与其父结点实施旋转操作。很明显这可以将一个很深的叶结点推向 root,但其父结点也被推向了与其差不多的深度。
伸展
伸展 (splaying) 的方法类似于旋转,不过在从底向上的旋转上,有些其他操作。
令 X 是访问路径上的非根结点,在这个路径上实现旋转。如果 X 的 parent 是树根只需要旋转 X 与其 parent 即可;否则需要考虑如下情况:
- 之字形 (zig-zag):只需要像 AVL 一样执行双旋转
- 一字形 (zig-zig):将 X 作为根,父结点和祖父结点分别是其孩子的结点,多余子结点向上过继

B树
我们一直认为始终将数据存储于 RAM 中,而不是磁盘中,但如果数据太大以至于不得不放在磁盘时,大 \(\mathcal{O}\) 模型将不再适用。因为 \(\mathcal{O}\) 认为所有操作是相等的,但是涉及磁盘 IO 时,它的代价实在太高了。绝大多数情况下控制运行时间的是磁盘访问次数,因此我们更愿意一次从磁盘中取出大量数据并进行大量计算。
假设你现在将一棵 1000 万个结点的 BST 存储于磁盘之上,显然一棵不平衡的 BST 可能让你访问磁盘 1000 万次;如果你的存储结构是 AVL 树,那会好很多,绝大多数情况下你只需要 \(\log_{}{N}\) 而非 \(1.44 \log_{}{N}\) 次磁盘访问,这大概是 25 次磁盘访问。如果可以将这 1000 万结点的树,压缩到一个非常小的常数,哪怕是一个非常复杂的数据结构,对于 CPU 来说也是不成问题的。显然二叉树并不是一个好的选择,存储层数最低的完全二叉树的高度是 \(\log_{}{N}\) 。如果我们增加树的 degree,那么树的分支会极大增加,而深度却会急剧减少。这样的 M 路分支树被称为 M叉查找树 (M-ary search tree),可以明确的是 compelete M-ary tree 的高度是 \(\log_{M}{N}\) 。
为了防止 M-ary tree 退化,我们会为其加入更加严格的平衡条件,以保证其它的平衡。 1970 年 Rudolf Bayer 与 Edward M. McCreight 在波音研究实验室 (Boeing Research Labs) 发现了自平衡的 B树 (B-tree)。不过不像其他结构那样,两位作者都没有给出这里 B 的含义,你可以认为是 Balanced、Bayer 甚至是 Boeing,不过 Knuth 在 1980 年发表的论文 CS144C classroom lecture about disk storage and B-trees 中推测其中的含义可能是后两种。
B树的相关术语与定义
实际上对于 B 树的相关定义与术语并不统一,阶 (order) 被 Knuth 定义为最大数量的子节点 (即最大数量的键加一)。Bayer 认为叶子层是最下面一层的键,而 Knuth 认为叶子层是最下面一层键之下的一层。而在实现上,叶子可能保留了完整的数据记录,也可能只保留了指向完整数据记录的指针。
根据 Knuth 的定义,一个 m 阶 B 树具有以下属性:
- 每个结点最多有 m 个子结点
- 除根外的所有内部结点最少有 \(\lceil\frac{m}{2}\rceil\) 个子结点
- 如果根结点不是叶结点,那么它至少有两个子结点
- 有 k 个子结点的非叶子结点拥有 \(k - 1\) 个键
- 所有的叶子结点都在同一层

我们定义一个结点最少拥有的子结点数 \(L = \lceil\frac{m}{2}\rceil\) ,而最多拥有的子结点数 \(U = m\) ;而包含的元素的个数最少 \(\lfloor\frac{m}{2}\rfloor\) 个,最多 \(m - 1\) 个。
- 根结点
- 拥有子结点数量的上限与内部结点相同,但没有下限。当树的元素数量小于 \(L - 1\) 时,根结点是唯一结点且没有任何子结点
- 叶子结点
- 没有子结点或指向子结点的指针,当然能存储的最大元素数依然是 \(m-1\)
- 内部结点
- 除叶结点与根结点外的所有结点,它们通常被表示为一组有序的元素和指向子结点的指针。每一个内部结点含有的子结点范围为 \([L, U]\) ,含有元素的数量在 \([L - 1, U - 1]\) ,而 \(U = 2L\) 或 \(U = 2L - 1\) ,因此所有内部结点至少是半满的
一个深度为 \(n+1\) 的B树可以容纳的元素数量大约是深度为 n 的B树的 U 倍,但是搜索、插入和删除操作的开销也会增加,当然开销的增加速度是极为缓慢的。B树在每一个节点中都存储值,所有的节点有着相同的结构。然而,因为叶子节点没有子节点,所以可以通过使用专门的结构来提高B树的性能。
B树的插入操作
对于所有平衡树来说,其都是建立在 BST 的基础之上,因此插入一个元素时都需要从根结点开始,找到新元素应该被添加的位置。当找到要插入的结点时,将会有以下情况:
-
如果结点拥有元素数量小于最大值,那么有空间容纳新元素,将元素插入到这一结点,并保持结点中的元素有序

-
否则这个结点已满,将它平均分裂成两个结点:
- 从该结点的原有元素和新元素中选择出中位数
- 小于这一中位数的元素放入左边结点,大于的元素放入右边结点
- 中位数元素将会被插入到父结点中,插入过程以同样的方法递归向上进行,直到元素被插入到树中。如果最终插入根结点但其已满,选出中位数作为新的根,将根结点分裂为两个结点作为新根的子结点
B树的移除操作
由于 B 树也是一种 BST,因此移除非叶结点时,也先将其交换到叶结点之后再进行移除操作。因此重点是将移除叶结点,然后调整树的约束条件使其满足。
- 移除B树叶子结点中的元素,发生下溢出不满足B树约束时,进行再平衡
- 由于内部结点的元素是左右两个子树的中间值,因此需要合并这两个子树,但可以肯定的是,左子树的所有元素依然小于右子树中的所有元素。
- 选择一个新的中间值 (左子树的最大值或右子树的最小值),将其替换掉被移除的元素,需要注意的是贡献新中间值的结点为叶子结点
- 判断贡献中间值的叶结点是否满足约束,如果不满足则从该叶子开始再平衡
可以发现,所有需要再平衡的结点都是从叶结点开始的,并向根结点进行,直到树重新平衡
- 如果缺少元素结点的右兄弟存在且拥有多余的元素,那么进行左旋
- 将中间值复制到左子结点的最后
- 将中间值替换为右子结点的最小元素,并从右子结点中移除该元素
- 树已再次平衡,结束操作
- 否则,如果缺少元素结点的左兄弟存在且拥有多余的元素,那么进行右旋
- 将中间值复制到右子结点的开始
- 将中间值替换为左子结点的最小元素,并从左子结点中移除该元素
- 树已再次平衡,结束操作
- 否则,将其与一个直接兄弟结点以及中间值进行合并
- 将中间值、左子结点、右子结点都合并到一个结点上 (假设为左子结点),并将中间值和右子结点从父结点中移除
- 判断当前父结点的情况
- 如果父结点是根且父结点中没有其他元素,则将合并之后的结点作为新的根
- 如果父结点不是根,且父结点满足约束,则树已再次平衡,结束操作
- 如果父结点不满足内部结点的要求,对父结点进行再平衡操作。如果有多余的子树,则将这棵子树旋转给不平衡结点即可

B+树
B+树 (B Plus Tree) 是 B Tree 的一个变种。有人将 B-Tree 读作 B减树 是不正确的,
B-Tree 中的 - 是一个连字符。既然是变种,那就有差异:
- 内部结点不再存储数据,只对其键进行存储,用以查找叶结点,数据全部由叶子结点存储
- 叶结点之间采用指针相连,你可以顺序从叶结点的头部遍历到尾部,而不需要其他额外的操作
如何选取键作为父结点的元素可以快速查找子结点,最简单的方法就是选取左子结点的最大值或右子结点的最小值,一般根据实现进行选择。

对 B+ 树操作时,与 B 树几乎一致,但区别是 B+ 树需要从叶结点开始递归向上,且 B+ 树需要修改父结点的分割值,而 B 树不用。
红黑树
红黑树 (red-black tree) 是一种自平衡二叉树,于 1972 年由 Rudolf Bayer 发明,发明时被称为 对称二叉 B 树,现代名称红黑树来自 Knuth 的博士生 Robert Sedgewick 于 1978 年发表的论文。红黑树的结构复杂,但操作有着良好的最坏情况运行时间:它可以在 \(\mathcal{O}(\log_{}{N})\) 时间内完成查找、插入和删除操作。
红黑树是具有下列着色性质的 BST:
- 每个结点要么是黑色要么是红色
- 根是黑色的
- 如果一个结点是红色的,那么它的子结点必须是黑色的
- 从一个结点到一个 NULL 指针的每一条路径都必须包含相同数目的黑色结点
根据着色规则,red-black tree 高度最多是 \(2\log_{}(N+1)\) ,因此查找保证是一种对数的操作。当然还有一条约定,空结点 nullptr 我们假设其为黑色,这样我们可以在不违反约定的情况下,方便操作。

通常困难在于将一个插入一个新结点后,如果将结点涂为黑色将违反性质 4,因为这会让路径上的黑色结点数量加一,但其他路径上黑色结点数量不变。
因此在插入结点时,默认结点为红色,父结点为黑色时,直接插入。在以下的情况中不再讨论这种情况。父结点是红色则会违反规则 3,在这种情况下必须修改树以满足所有性质。
红黑树的自底向上插入
如果新插入的结点 X 是红色的,它有父结点 P,兄弟结点 S,叔父结点 U,以及祖父结点 G。那么需要考虑几种情况:
- 如果 P、U 都是红色的,意味着 G 是黑色的,可以将 P、U 重绘为黑色将 G 重绘为红色,这样既不会违反规则 3 也不会违反规则 4。但是 G 之上的情况我们不知道,G 也可能是根,因此需要对 G 进行递归地向上进行重绘操作
- 如果 P 与 U 只有一个是红色的,意味着 G 是黑色的,而插入的 X 虽然不违反规则 4 但是违反了规则 3,迫使 X 或 P 变为黑色,而这样又会违反规则 4。为了让树再次符合要求,我们对其需要进行旋转操作并重绘结点颜色,其实这里的旋转操作与 AVL 树中是一致的,只是将结点的平衡因子转换为了颜色信息。 a. 当 X、P、G 形成 zig-zig 时,我们采用 single rotation b. 当 X、P、G 形成 zig-zag 时,我们采用 double rotation
// 该函数仅处理父结点是红色的情况,黑色情况则直接插入即可
// 使用头结点方便处理,头结点的 parent 指向 root,root 的 parent 指向 head
void insert_help(Node* node, Node* head) {
// 当结点不是树的根或父结点是红色时,进行循环
while (node != head->parent && node->parent->tag == RED) {
Node* uncle = get_uncle(node);
Node* grandparent = get_grandparent(node);
Node* parent = node->parent;
// 如果叔父结点不为空且为红色,符合情况 1
if (uncle != nullptr && uncle->tag == RED) {
parent->tag = uncle->tag = BLACK;
grandparent->tag = RED;
node = grandparent;
continue;
}
// 判断 zig-zig 或 zig-zag 类型,进行相应的旋转
if (parent == grandparent->left) {
if (node == parent->right) { // l-r 的 zig-zag
node = parent;
parent = rotate_left(parent);
}
rotate_right(grandparent); // l-l 的 zig-zig
} else {
if (node == node->parent->left) { // r-l 的 zig-zag
node = parent;
parent = rotate_right(parent);
}
ratate_left(grandparent); // r-r 的 zig-zig
}
grandparent->tag = RED;
parent->tag = BLACK;
}
head->parent->tag = BLACK;
}红黑树的自顶向下插入
自底向上的操作需要父指针或栈保存路径,而自顶向下时实际是对红黑树应用自顶向下保证 S 不会时红色的过程。
在向下的过程中,如果结点 N 有两个红色的孩子时,将孩子重绘为黑色,结点 N 重绘为红色。结点 N 与其父结点 P 都为红色时,将违反红黑树的着色性质,此时对其进行 zig-zig 或 zig-zag 旋转即可。至于叔父结点 U 在自顶向下的过程中排除了红色的可能。
// 自顶向下插入,value 是待插入的值
void insert(Node* node, Node* head, T& value, Node** pos = nullptr) {
bool inserted = false;
if (node == nullptr) { // 插入结点,默认为红色
node = new Node(value);
*pos = node;
inserted = true;
}
if (node->left != nullptr && node->left->tag == RED &&
node->right != nullptr && node->right->tag == RED) {
node->left->tag = node->right->tag = BLACK;
node->tag = RED;
}
head->parent->tag = BLACK;
Node* gp = get_grandparent(node);
Node* parent = node->parent;
if (node->tag == RED && parent->tag == RED) {
// 判断 zig-zig 或 zig-zag 类型,进行相应的旋转
if (parent == gp->left) {
if (node == parent->right) { // l-r 的 zig-zag
parent = rotate_left(parent);
}
rotate_right(gp); // l-l 的 zig-zig
} else {
if (node == parent->left) { // r-l 的 zig-zag
parent = rotate_right(parent);
}
ratate_left(gp); // r-r 的 zig-zig
}
gp->tag = RED;
parent->tag = BLACK;
}
if (inserted) {
return;
}
if (node->val < value) {
insert(node->left, head, &node->left, value);
} else {
insert(node->right, head, &node->right, value);
}
}红黑树的自顶向下删除
删除结点时,所有情况都可以归结于删除一个叶结点,因为删除带有两个孩子的结点,都可以与其左子树最大结点或右子树最小结点的值进行交换,这只改变了值没有改变颜色,并不影响红黑树的性质。之后删除交换后的叶结点即可。对于红色叶结点,我们可以将其直接删除,这不影响红黑树的结构,如果有孩子我们只需要用其孩子代替它即可。如此我们需要保证在自顶向下过程中保证叶结点是红色的。
假设当前结点是 N,其兄弟结点 S、父结点 P、叔父结点 U 和祖父结点 G。开始时需要将树根重涂为红色,沿树向下遍历,当到达一个结点时,确保 P 是红色、N 和 S 是黑色。在此过程中会遇到一些情况:
- N 有两个黑色的孩子,此时 a. S 也有两个黑色的孩子,那么重涂反转 N、S、P 的颜色,树结构不变 b. S 有红色的孩子,根据红色的孩子进行 signal rotate 或 double rotate。如果两个孩子都是红色,任选一个进行旋转即可
- N 有红色的孩子,此时向下递归 a. 新的 N 是红色,继续递归 b. 新的 N 是黑色,对 S 和 P 进行旋转,S 成为 P 的父结点,重绘 P 与 S 的颜色,即可得到红色的父结点 P。对于 P 来说,回到情况 1
AA 树
二叉B树 (Binary B-tree) 是一种简单但颇有竞争力的实现,被称为 BB 树,可以理解为带有附加条件的红黑树:一个结点最多有一个红色的孩子。

当然还有一些法则:
- 只有右孩子可以是红色的,这样总可以使用内部结点的右子树的最小结点代替该结点
- 递归地编写过程
- 信息存储在整数中,而不是 bit 与每个结点一起存储。这个信息主要是结点的层次信息 a. 若是 1,则该结点是叶结点 b. 是父结点的层次,则该结点是红色的 c. 比父结点的层次少 1,该结点是黑色的
简单地,我们就可以得到一颗 AA 树。并且左孩子必然比其父结点低一个层次,右孩子可能比父结点低 0 或 1 个层次,但不会更多。
struct AANode {
Comparable element;
AANode* left;
AANode* right;
int level;
AANode() : left(nullptr), right(nullptr), level(1) {}
AANode(const Comparable& e)
: element(e), left(nullptr), right(nullptr), level(1) {}
};AA树的插入操作
水平链接 (horizontal link) 是一个结点与同层次上的孩子所建立的链接,这种水平链接都是右链接,并且不含有两个连续的水平链接。

不过这有一些情况需要注意,插入新结点时,可能导致左水平链 (插入 2) 或连续两个右水平链 (插入 45)。通过右旋可以消除掉左水平链,而左旋则可以消除多余的右水平链,这两个过程分别称为 skew 和 split。
由于新建了一个左水平结点或连续右水平结点,会引起结点 N 的原始父结点 P 的一些问题,这些问题可以通过上滤 skew/split 的方法解决。
void skew(AANode* node) {
if (node->left->level == node->level) {
rotate_right(node);
}
}
void split(AANode* node) {
if (node->right->right->level == node->level) {
rotate_left(node);
++node->level;
}
}有了上述基础,AA 树的插入操作可以说是相当简单,和非平衡 BST 的插入实现基本一致。
void insert(const Comparable& val, AANode*& root) {
root == nullptr ?
static_cast<void>(root = new AANode(val)) :
insert(val, val < root->element ? root->left : root->right);
skew(root);
split(root);
}AA树的删除操作
删除操作对比插入操作就会复杂许多。但是值得注意的是,我们为了编程更加容易增添了一些法则,这些法则为我们去除了一些特殊情况。可以肯定,若结点不是叶结点,那么它一定有右结点,那么在删除操作时,总可以使用右子树上最小的孩子替代这个结点,保证它是在第一层。在递归过程中,非叶结点的层次可能会被破坏,实际上只有递归路径上的子结点可能受到影响,我们依然需要处理这些情况。
实际上,只需要三次 skew 与两次 split 就可以完全重新安排这些水平的边。
void remove(const Comparable& val, AANode* root) {
if (root == nullptr) {
return;
}
static AANode* last_node = root; // 寻找替换结点
static AANode* deleted_node = nullptr; // 待删除结点
if (val < root->element) {
remove(val, root->left);
} else {
deleted_node = root;
remove(val, root->right);
}
if (root == last_node) {
// 如果 val 结点是叶结点,直接删除
if (deleted_node == nullptr || val != deleted_node->element) {
return;
}
deleted_node->element = root->element;
deleted_node = nullptr;
root = root->right;
delete last_node;
} else {
// 不是树的底部,需要对其进行平衡
if (root->left->level < root->level - 1 ||
root->right->level < root->level - 1) {
if (root->right->level > --root->level) {
root->right->level = root->level;
}
skew(root);
skew(root->right);
skew(root->right->right);
split(root);
split(root->right);
}
}
}