GPU 基础介绍
该篇介绍主要以 AMDGPU 7900XTX (Navi31) 为例。
GPGPU 模型简介
SIMT 模型
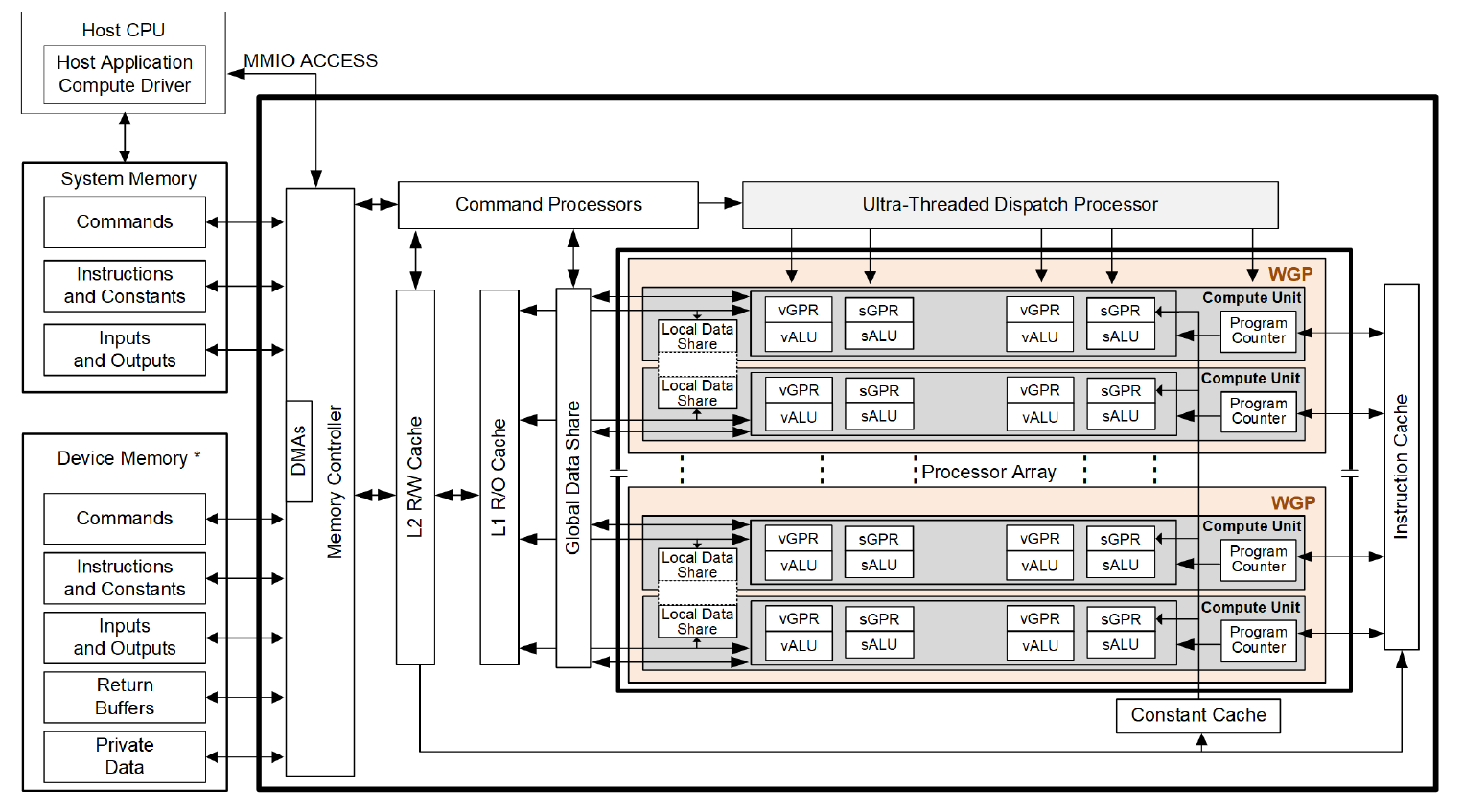
现代 GPU 上基本使用 SIMT (单指令多线程, Single Instruction Multiple Threads) 模型,即一条指令执行在多个线程 (thread / lane / invocation) 上,每个线程上可能存储、运算不同地数据,也就是说具有大规模并行计算的能力。
在 SIMT 模型上,由于指令是一次性发送到多个线程上,因此需要一个管理线程的单元。在 Vulkan 中将其称其为 subgroup,在 DirectX 或 AMDGPU 上被称为 wavefront,Nvidia 将其称之为 wrap。Subgroup 是 GPU 上的最小控制单元,即使我们需要一个线程,我们也只能向 GPU 申请使用一个 subgroup。
AMDGPU 上 subgroup 的最小是 32 个线程 (wave32),但是可以使用 2 个 wave32 组成一个 wave64 使用。以下无特殊说明,subgroup 以基础的 wave32 介绍。
SIMD 执行单元是一个更大层级的单元,根据 AMDGPU 公开的 RDNA 资料,一个 SIMD 上有 16 个 ALU (算术逻辑单元,Arithmetic logic unit),也就是 16 个 subgroup。另外一些更上层的控制单元简单地列举:
- CU (Compute Unit) 包含 2 个 SIMD
- WGP (Work-group Processor) 包含 2 个 CU
- SA (Shader Array)
- SE (Shader Engine)
在 AMDGPU 的公开手册 2.3. Work-groups 中详细说明了 CU 与 WGP 的区别。
寄存器
寄存器是计算机体系中的重要概念,因为只有寄存器可以被 ALU 直接使用,而存储在其他地方的数据,只有先加载进寄存器中才可以使用。另外,寄存器由于是距离 ALU 最近的存储结构,因此也是整个体系结构中存储大小最小,但最高效的存储结构。
在 AMDGPU 上每个寄存器 32 bit,或者称其为 1 DWORD。
VGPR
在 SIMT 模型中介绍了基础结构,比如我们有指令 v0 = add float v1, v2,虽然只使用了
3 个寄存器,实际上在整个 subgroup 上每个线程都需要有这三个寄存器。也就是说,在
subgroup 上至少需要 3*32*4 字节的存储空间。如果 subgroup 设置为 wave64,那么将两个 wave32 的寄存器拼为一个 wave64 所使用的寄存器。
这种寄存器被称之为 VGPR (向量通用寄存器,Vector General Purpose Register),被用于各种 SIMT 运算。这些 VGPR 被存储在一个被称为 Vector Register File 的 SIMD 的私有内存上。
每个 subgroup 最多使用 256 个 VGPR,SIMD 上最多有 1536 个 VGPR (Navi31)。可以计算出,如果程序使用少于 96 个 VGPR,那么我们可以使用所有的 subgroup。但是当程序使用 256 个 VGPR 时,也就是说最多只有 6 个 subgroup 可以同时运行。
SGPR
如果说我们有一组在 subgroup 上都相同的数据,那么对于它的计算并不需要使用 SIMT 模型。这时候就需要引入 SALU,即一个 subgroup 上每个线程看到的数据和指令都相同的。通常,GPU 上可以认为 Scalar 指令总比 Vector 指令高效。
无论是 wave32 还是 wave64,每个 subgroup 可以使用 106 个 SGPR,以及 22 个特殊 SGPR:
- 106 个通用 SGPR (s0~s105)
- VCC_LO 和 VCC_HI (s106, s107)
- 用于处理 trap 的 16 个 Trap Temporary (TTMP0
TTMP15, s108s120) - NULL (s124)
- M0 (s125)
- EXEC_LO 和 EXEC_HI (s126, s127)
Alignment 与 Bank
VGPR 的使用是按照块分配的,即每个 subgroup 一次最少向 Vector Register File 申请的数量,在 Navi31 上是 24 个 VGPR,这个数字在 wave64 上砍半。
VGPR 有 4 个 bank,当一条指令上的多个 src (源操作数) 来自同一个 bank 时,对于这些数据的加载是阻塞的,我们将其称之为 Bank Conflict。也就是说,只有当下一个周期时,指令才可以将下一个源操作数加载进 ALU。
示例:考虑 v0 = mad i32 v0, v1, v3 和 v0 = mad i32 v0, v4, v8。前者只需要一个周期就可以准备好数据,而后者需要三个周期用于准备数据。因为 v0 / v4 / v8 属于同一个
bank。
SGPR 每次读取 8 字节数据,换句话说,SGPR 总是偶数对齐的。
控制流
无论对于什么编程语言来说,控制流 (Control Flow) 都是一个重要的概念。对于 GPU 来说,控制流是发生在一个 subgroup 上的,因此我们无法精细化地控制每个线程。
当发生分支跳转时,AMDGPU 使用 EXEC 掩码来区分 subgroup 中的哪些线程是需要执行的,而另一些是不需要执行的。因此在 GPU 上,分支是相对高代价的操作,当执行一个分支时,另一部分线程可以被认为是完全不执行代码的。
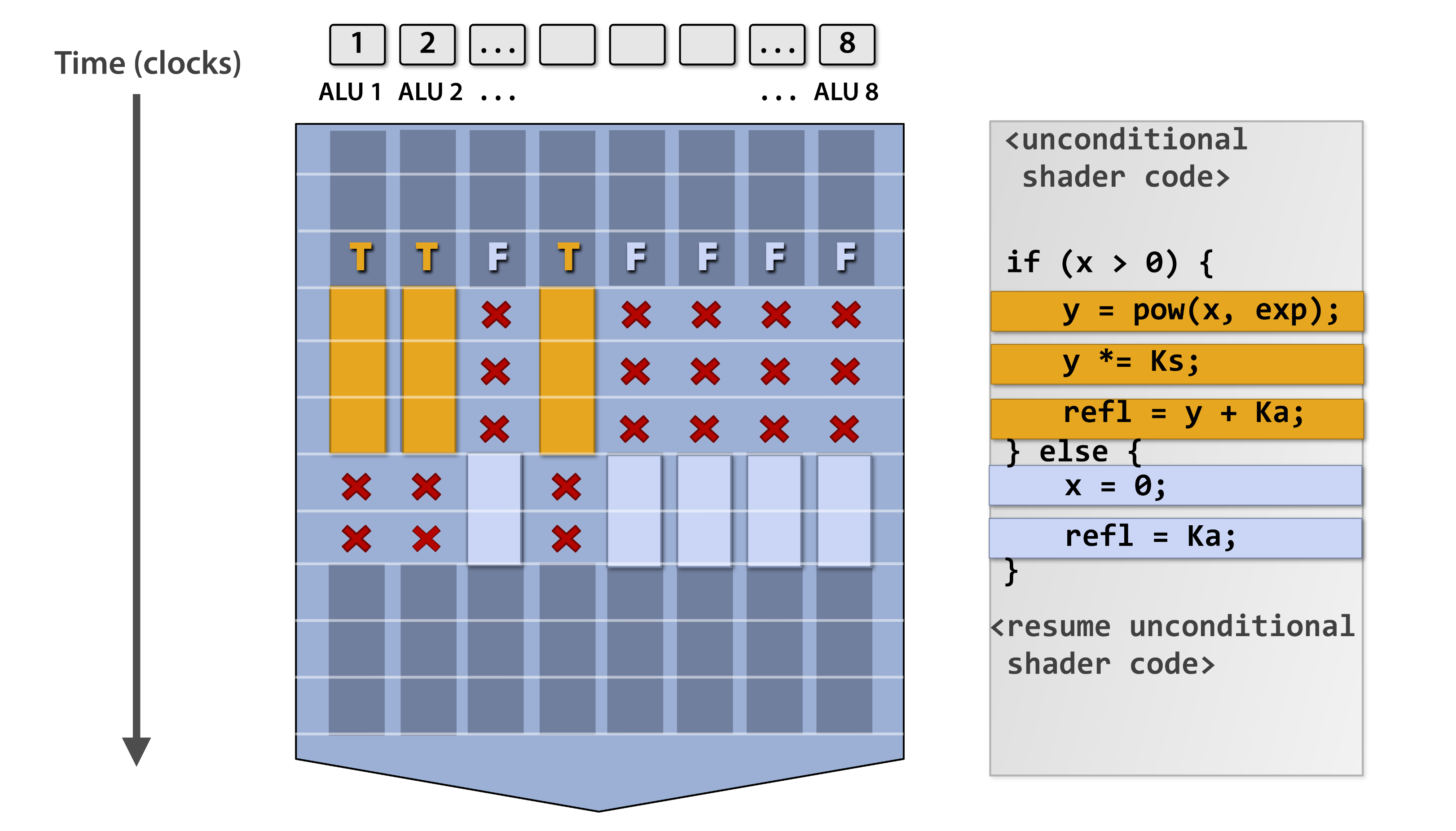
Divergent 与 Convergent
简单地说,如果分支条件是 VALU 产生的 (e.g. v_cmp_eq_i32),那么这个分支被称为
divergent。此时只有一部分线程可以进入该分支,这一部分线程被称为 active,而那部分未进入的被称为 inactive。
通常,使用寄存器 EXEC 和 VCC 来进行跳转:s_cbranch_execz / s_cbranch_vccnz 等。
Vector 指令只会在 active 线程上执行,而 inactive 线程会忽略这些指令。对于 Scalar
指令,由于它是整个 wave 共享的,因此可以被认为是总是执行的。
在 SpirV 中有一个非常重要的概念 – Merge。这意味着,分支结构在 Merge Block 中发生 Convergent。
// EXEC = 0xF0F0
if (divergentCond) {
// EXEC = 0xF000
} else {
// EXEC = 0x00F0
}
// EXEC = 0xF0F0另一种分支是由 SALU (e.g. s_cmp_eq_i32) 产生的,通常被写入状态寄存器的 SCC
(Scalar Condition Code) 中,用于整个 subgroup 的跳转,一般情况下这时并不会出现
EXEC 的变化。
Waterfall Loop
Waterfall loop 是一种特殊的循环结构,它通常由编译器产生,用于将特定 Vector 数据提升为 Scalar 数据,相同数据的线程同时执行,不同数据的线程依次执行。典型应用是 Vulkan 的 NonuniformEXT。
// V0 holds the index value per lane
// save exec mask for restore at the end
s_mov_b64 s2, exec
// exec mask of remaining (unprocessed) threads
s_mov_b64 s4, exec
loop:
// get the index value for the first active lane
v_readfirstlane_b32 s0, v0
// find all other lanes with same index value
v_cmpx_eq s0, v0
<OP> // do the operation using the current EXEC mask. S0 holds the index.
// mask out thread that was just executed
s_andn2_wrexec_b64 s4, s4
// repeat until EXEC==0
s_cbranch_scc1 loop
s_mov_b64 exec, s2线性控制流
由于 GPU 的特性,实际上代码在 GPU 上类似于线性执行,因此在编译后期 (backend) 通常会加入线性控制流 (Linear Control Flow)来表示 BB 关系。
.entry:
br i1 %cond, label %.then, label %.else
.then:
; do something
br label %.endif
.else:
; do something
br label %.endif
.endif:不同于 CPU 上要么执行 .then 分支要么执行 .else 分支,GPU 上实际是一部分线程先执行 .then 而另一部分线程再执行 .else。
.entry:
%0 = save_exec
br label %.then
.then:
%exec = and i32 %exec, %vcc
; do something
br label %.else
.else:
%exec = andn2 i32 %0, %exec
; do something
br label %.endif
.endif:
%exec = %0共享内存
shared memory,或称为 LDS (Local Data Share)。通常这是 Compute Shader 中的声明为 shared 的全局变量,或者 CUDA 中的 shared memory。该类型变量可以在一个 workgroup 中共享,即 shared 变量的修改可被在同一 workgroup 中的所有线程观察到。
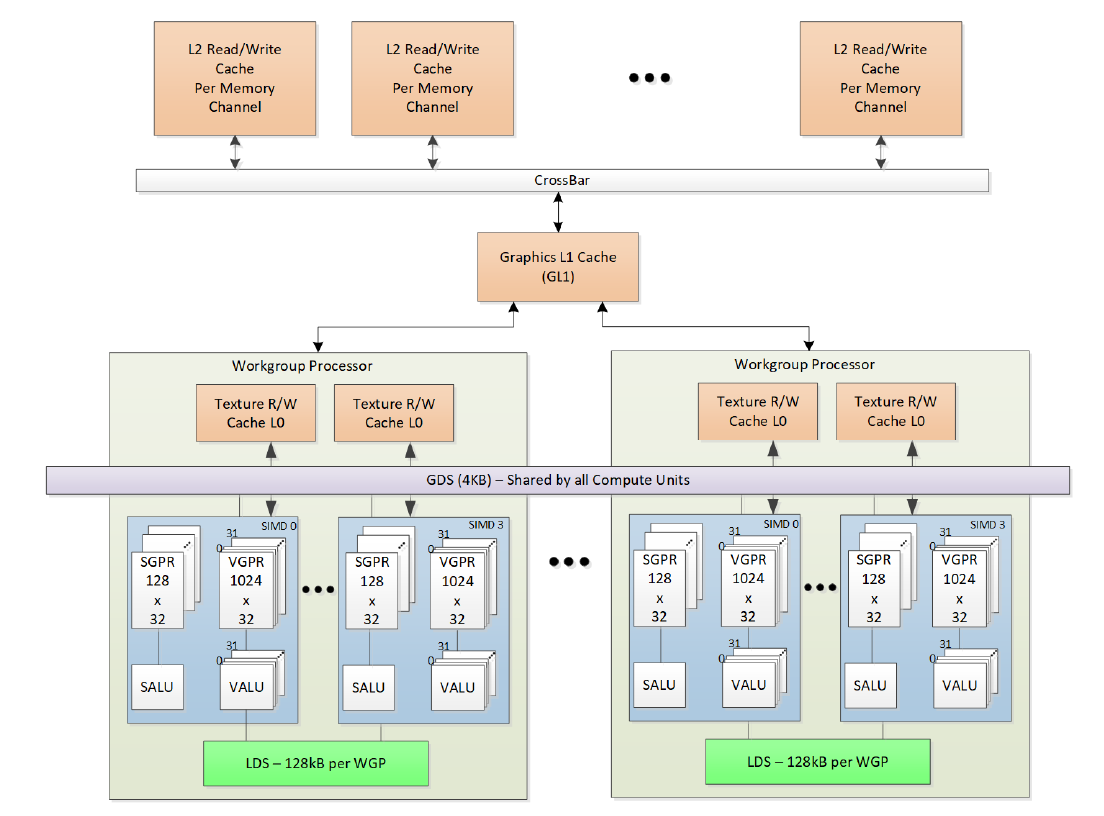
LDS 是一个大小为 128 KiB,由 2 个 CU 共享的片上 (On-Chip) 高速内存。分配大小为 1024 字节,配置为 64 个 bank。需要特别注意的是,在 CU Mode 下,实际上 LDS 是按照高低两部分平均分配给 2 个 CU 的,因此每部分的总大小 / bank / 分配大小等是配置一半,且 2 个 CU 无法访问对方的 LDS。
而 GDS (Global Data Share) 是由整个 GPU 所有单元共享非片上 (Off-Chip) 4 KiB 内存,通常其被用于同步 (e.g. GS Stream)。
缓存
分级缓存
Cache 通常被认为是程序不可见的,但在计算机体系结构中 Cache 起到了相当重要的作用。由于越靠近 ALU,存储单元速度越快,但由于价格与芯片面积的限制,这类存储单元也不会过于巨大。因此 On-Chip 多级缓存的概念应运而生:
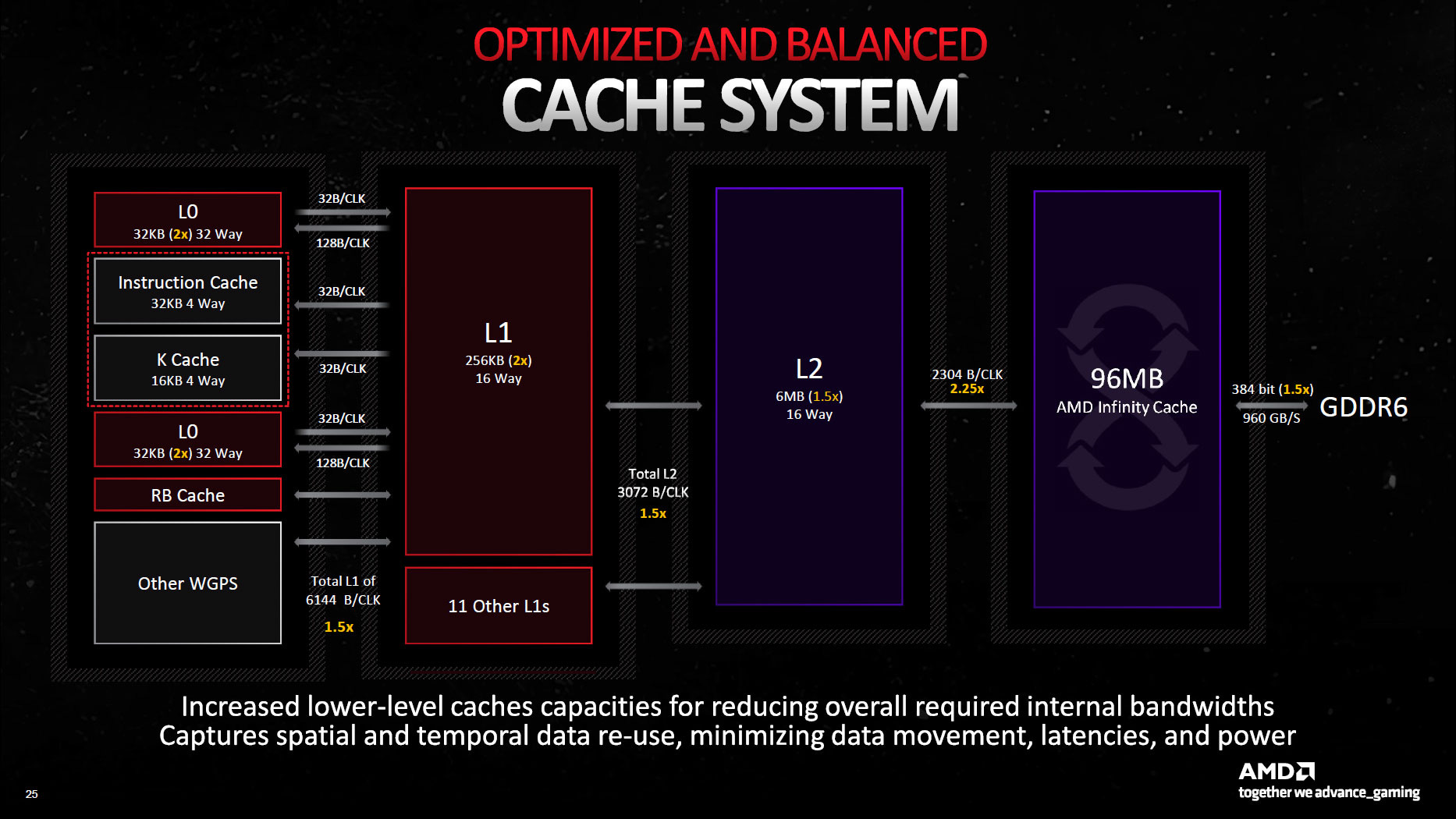
| Kind | Size | Cache Line Size | Readable |
|---|---|---|---|
| Instruction Cache | 32 KiB per WGP | 64 Bytes | RO |
| Scalar/K Data Cache | 16 KiB per WGP | 64 Bytes | RO |
| L0 Cache | 2x32 KiB per WGP | 2x128 Bytes | RO |
| L1 Cache | 256 KiB per SA | 64 Bytes (?) | RO |
| L2 Cache | 6 MiB 16-way set-associative | 64 Bytes (?) | RW |
访存优化
当进行访存操作时,逐级访问 Cache,直到向内存发送访存请求。加载数据时,总是读取一个 Cache Line 的数据大小,即我们常说的局部性原理。当再次访问该地址附近的内存时,只需要从 Cache 中加载到寄存器,而不需要再进行漫长的访存等待,因此编译器倾向于将地址相近的访存指令排列在一起。
对于存储的数据进行优化也可能会影响性能,其主要是由于 Bank Conflict 以及 GPU 的访存特性引起的。因此上层应用也会在某些时候对内存数据布局进行优化。如 Graphics 中的 Texture swizzle lyaout 以及 CNN 中的 NCHW。
另外,当访存发生时,GPU 会发生 subgroup 级别的上下文切换,这类似于 CPU 上的阻塞进程切换。
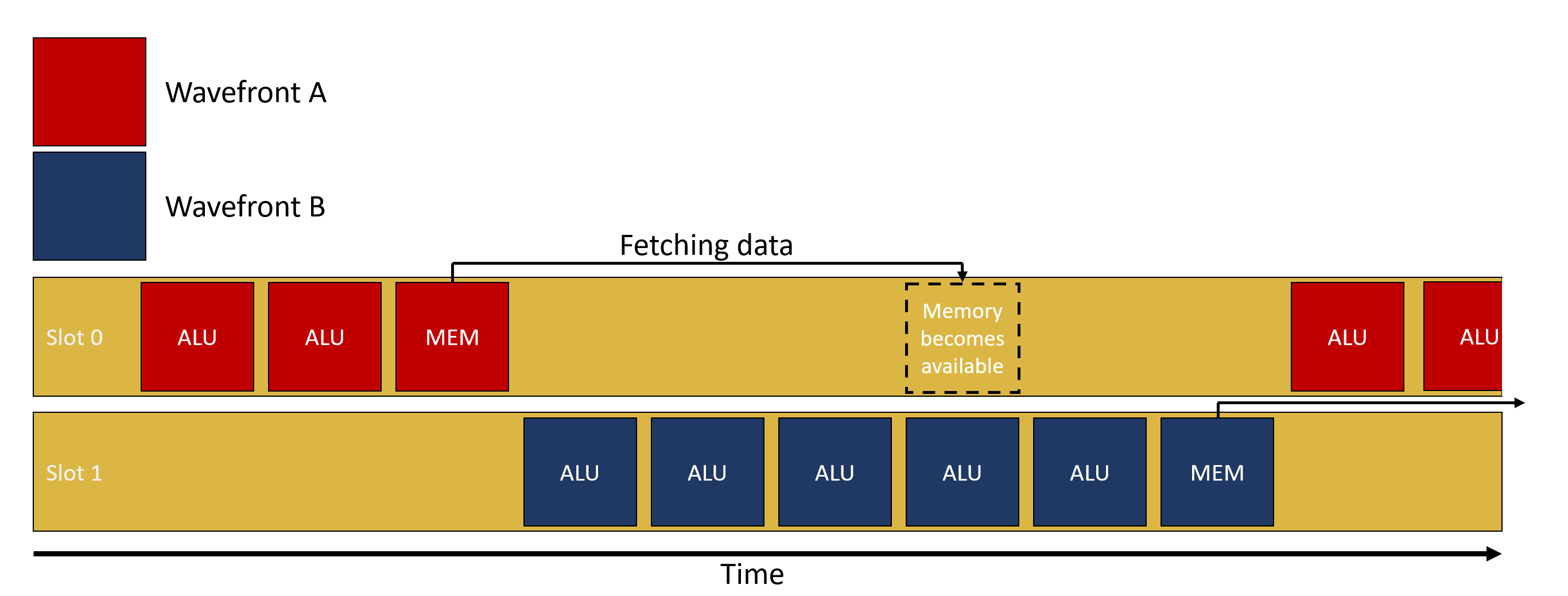
因此,编译器也会尽量将访存指令进行组合,以减少预期的上下文切换,且对性能有巨大的潜在提升。该优化在 LLVM 中被称为 GPU Load & Store Vectorizer
(lib/Transforms/Vectorize/LoadStoreVectorizer.cpp)。
; before
%0 = load <2 x i32>, ptr %1, i32 0
%1 = load <2 x i32>, ptr %1, i32 64
; after
%0 = load <4 x i32>, ptr %1, i32 0当面对多条无法向量化的访存指令,无法避免地会有多次上下文切换。RDNA 架构引入 Hard
Clause 后,backend 也倾向于将访存指令组合 (Group) 起来,插入 s_clause 显式告诉
HW 将有多少条连续的同类型访存指令。该指令可以带来缓存一致性以及上下文切换的好处。
(lib/Target/AMDGPU/SIInsertHardClauses.cpp)
s_clause 0x1
buffer_load_b128 v[0:3], v0, s[0:3] offset:0x100
buffer_load_b128 v[4:7], v8, s[0:3] offset:0xA00缓存控制
高级语言 (HLL, HighLevel Language) 中并不能感知到 Cache,但在高性能计算 (HPC, High Performance Computing) 领域,人们总是会考虑 Cache 的存在,利用局部性与避免 Bank Conflict 的方法提高程序性能。
对于编译器来说,我们有对访存指令控制缓存的方法:
- GLC
- 控制图形第一级缓存
- SLC
- 控制 L2 缓存
DLC :
这些控制位通常在 Memory Model 中非常有用。
体系结构
指令流水线 (Instruction Pipelining)
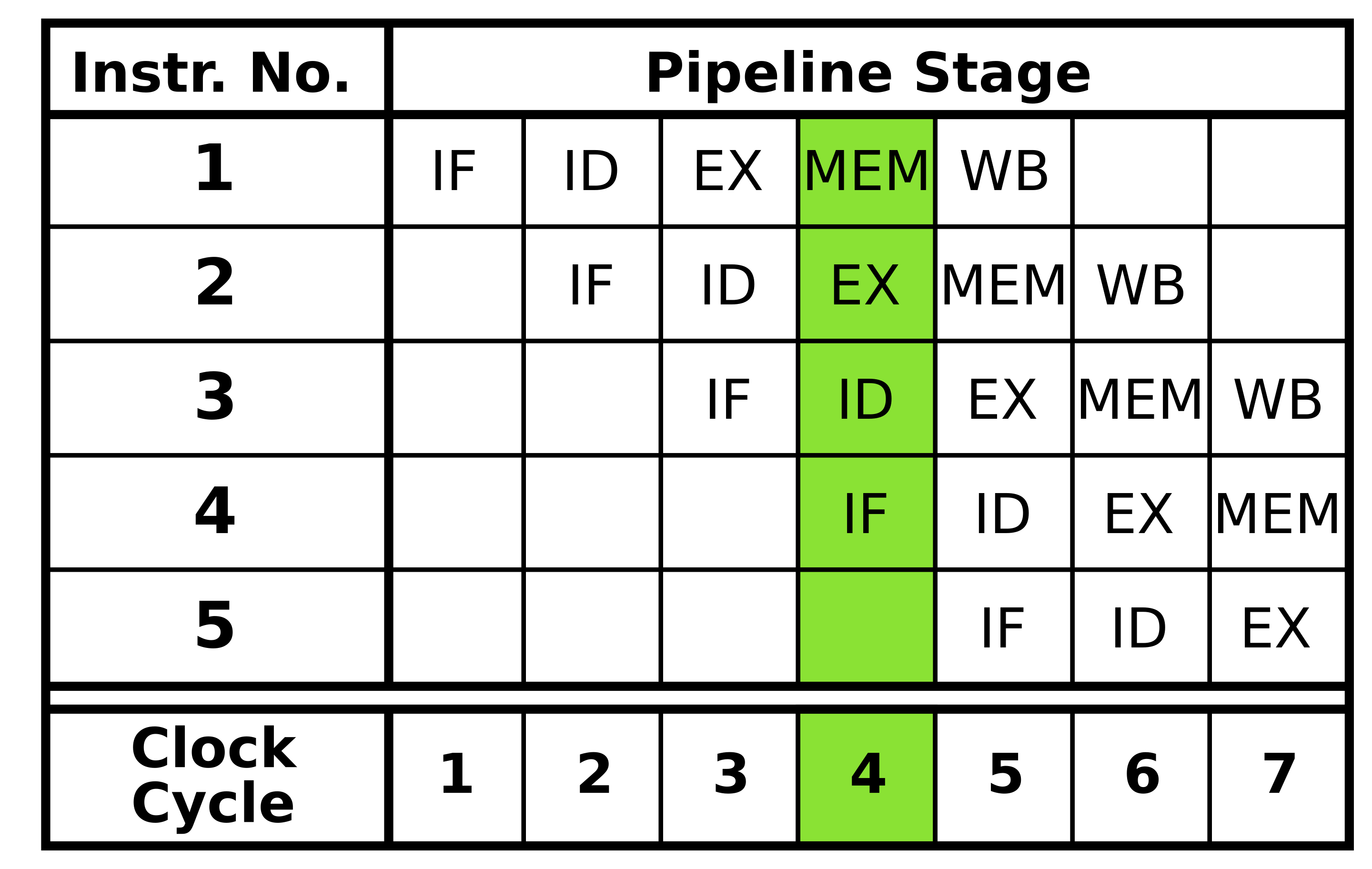
在现代 CPU 体系结构中,指令流水线是非常重要的结构,其中可能有多达十多级流水线,以提供高性能运算。最为经典的是 5 级流水线:
- IF (Instruction Fetch) 指令读取
- ID (Instruction decode and register fetch) 指令译码与寄存器读取
- EX (Execute) 执行
- MEM (Memory Access) 访存
- WB (Register write back) 写回寄存器
数据冒险
当表现出数据依赖性的指令修改流水线不同阶段中的数据时,就会发生数据冒险 (Data hazards)。忽略潜在的数据冒险可能会导致竞争条件。在三种情况下可能会发生数据冒险:
- 写后读 (RAW, read after write) – true dependency
- 读后写 (WAR, write after read) – anti dependency
- 写后写 (WAW, write after write) – output dependency
- 读后读 (RAR, read after read) – false dependency,该情况不会发生数据冒险
假设有以下指令序列:
v0 = add v1, v2
v2 = mul v0, v3
; cycles 0 1 2 3 4 5 6 7 8
; add IF ID EX MEM WB
; mul NOP NOP NOP IF ID EX MEM WB上述示例是一则典型的 RAW,编译器必须保证数据写回 v0 后,才可以让下一条指令读取数据。
流水线冒泡 (Pipeline bubbling) 是通常处理数据冒险的方式,即发送空指令 (NOP) 来推迟数据依赖性指令的执行,从而保证数据的安全。因此编译器后端中 ISched (Instruction Schedule, 指令重排) 显得尤为重要,Sched 应该尽可能将非依赖性指令重排在一起,以保证流水线的满载。
SOPP 指令
在 AMDGPU 上,解决数据冒险的方式主要由一系列延迟性指令解决 – SOPP。SOPP 通常在 ISched 之后由后端插入。
当所有依赖关系满足时,SOPP 指令可能不会执行,或者说可以延迟 0 周期。
S_DELAY_ALU
在 SALU 和 VALU 依赖性指令之间插入延迟。该指令可以一次性显式指示两个 VALU 的数据依赖关系:
- INSTID0
- 下一条 VALU 指令依赖的指令
- INSTSKIP
- 跳过不需要延迟的 VALU 指令数量
- INSTID1
- 第二条 VALU 指令的数据依赖关系
以 vkcube 为例:
v_fmac_f32_e32 v6, s20, v1 ; 560c0214
v_fmac_f32_e32 v7, s21, v1 ; 560e0215
v_fmac_f32_e32 v8, s22, v1 ; 56100216
v_fmac_f32_e32 v3, s23, v1 ; 56060217
s_delay_alu instid0(VALU_DEP_4) | instskip(SKIP_3) | instid1(VALU_DEP_3) ; bf8701c4
; instid0: depends on v6
v_fmac_f32_e32 v6, s24, v0 ; 560c0018
; skip 3
v_fmac_f32_e32 v7, s25, v0 ; 560e0019
v_fmac_f32_e32 v8, s26, v0 ; 5610001a
v_fmac_f32_e32 v3, s27, v0 ; 5606001b
; instid1: depends on v7
v_mov_b32_e32 v1, v7 ; 7e020307s_add_u32 s0, s3, 7 ; 80008703
s_delay_alu instid0(SALU_CYCLE_1) | instskip(NEXT) | instid1(SALU_CYCLE_1) ; bf870499
; instid0: depends on s0
s_and_b32 s0, s0, -8 ; 8b00c800
; instid1: depends on s0
s_pack_ll_b32_b16 s0, 0, s0 ; 99000080
s_delay_alu instid0(SALU_CYCLE_1) ; bf870009
; instid0: depends on s0
s_bfe_u64 exec, -1, s0 ; 947e00c1S_WAITCNT
waitcnt 系列指令用于延迟等待事件或访存。它们依赖于对应的指令计数器,当计数器等于或低于指定的值时,程序继续向下执行。
- VMcnt: Texture SAMPLE、VMemory Load 及 VMemory atomic-with-return
- VScnt: VMemory Store
- LGKMcnt:
- LDS indexed operations
- SMemory
- GDS & GWS
- FLAT instructions (uses both LGKMcnt and either VMcnt or VScnt)
- Message
- EXPcnt
- LDS parameter-load and direct-load
- Exports
; VMcnt = 0, VScnt = 0, LGKMcnt = 0
s_load_b128 s[12:15], s[10:11], null ; f4080305 f8000000
; VMcnt = 0, VScnt = 0, LGKMcnt = 1
s_waitcnt lgkmcnt(0) ; bf89fc07
; VMcnt = 0, VScnt = 0, LGKMcnt = 0
buffer_load_b128 v[0:3], v5, s[12:15], 0 offen offset:64 ; e05c0040 80430005
; VMcnt = 1, VScnt = 0, LGKMcnt = 0
s_buffer_load_b128 s[8:11], s[12:15], 0x30 ; f4280206 f8000030
; VMcnt = 1, VScnt = 0, LGKMcnt = 1
s_buffer_load_b128 s[16:19], s[12:15], 0x20 ; f4280406 f8000020
; VMcnt = 1, VScnt = 0, LGKMcnt = 2
s_buffer_load_b128 s[20:23], s[12:15], 0x10 ; f4280506 f8000010
; VMcnt = 1, VScnt = 0, LGKMcnt = 3
s_buffer_load_b128 s[24:27], s[12:15], null ; f4280606 f8000000
; VMcnt = 1, VScnt = 0, LGKMcnt = 4
buffer_load_b64 v[4:5], v5, s[12:15], 0 offen offset:640 ; e0540280 80430405
; VMcnt = 2, VScnt = 0, LGKMcnt = 4
s_waitcnt vmcnt(1) lgkmcnt(0) ; bf890407
; VMcnt = 1, VScnt = 0, LGKMcnt = 0: v[4:5] may not return
v_mul_f32_e32 v6, s8, v3 ; 100c0608分支预测
分支处理能力是现代 CPU 的强项,其主要贡献是分支预测技术。简单地说,这是一项为了填满流水线而提前将分支中的指令载入流水线的操作。分支预测的准确性通常能达到 90%
以上。
br i1 %cond, label %.then, label %.endif
.then:
; do somethings
br label %.endif
.endif:如此分支,当执行到跳转指令时,CPU 不得不停下流水线等待运算结果,来确定接下来执行的指令序列。当加入分支预测功能后,CPU 会尝试预测一个极有可能进入的分支,并在跳转指令还未完成时,直接将该分支中的指令开始解析并执行。
如果分支预测正确,那么 CPU 将不受 pipeline bubbling 的影响,可以高效执行分支。如果预测失败,CPU 必须将现有流水线全部清空,再重新开始执行分支,这通常需要付出极大的代价。我们也将预测失败称为 控制冒险 (Control/Branch hazard)。
为了避免控制冒险,可以在分支条件之后插入流水线冒泡以保证足够的延迟,从而避免清空流水线。
指令预取
在现代计算机体系架构中,指令作为一种特殊的数据进行读取。在 .elf 文件中,指令被存储在只读的 .text 段中。PC (Program Counter) 用于指明下一个需要执行的指令。
指令预取可以提前将当前 PC 之前的一部分指令存储到 ICache 中,通常可以是 1 / 2 / 3
个 ICache Line 的大小 (共 64 / 128 / 192 Bytes)。该值可以通过 subgroup 的状态寄存器设置,或在程序中使用 S_SET_INST_PREFETCH_DISTANCE 显式设置。
由于指令预取的存在,且防止在程序即将结束时预取出的指令无效,AMDGPU spec 推荐使用
256 Bytes 的 S_CODE_END 来填充程序。
GPGPU (General-purpose computing on graphics processing units)
- Compute Shader on Vulkan / OpenGL / D3D
- OpenMP / OpenACC
- OpenCL / SYCL / CUDA / RCOm / OneAPI
Workgroup 与 Subgroup
工作组 (workgroup) 是 compute shader 中的概念,由 local_size_(x|y|z) 声明该
workgroup 的大小。在 AMDGPU 上,一个 workgroup 最多可以有 1024 个线程,即 1 个
CU。如 Compute shader 可以一次性派发 (Dispatch) 多个 workgroup,即
glDispatchCompute。
线程标识
对于 workgroup 和线程编号,有以下定义:
const uvec3 gl_WorkGroupSize: 用于存储当前 workgroup 的大小,即程序中指定的local_size_(x|y|z)。in uvec3 gl_LocalInvocationID: 工作组内的每个线程的三维索引,范围在uvec3(0)和gl_WorkGroupSize - uvec3(1)之间。in uvec3 gl_NumWorkGroups: 由glDispatchCompute产生的全局工作组数量,三个 channel 分别是该函数的参数。in uvec3 gl_WorkGroupID: 工作组在全局范围内的三维索引,范围在uvec3(0)和gl_NumWorkGroups - uvec3(1)之间。in uvec3 gl_GlobalInvocationID: 表示当前线程在全局工作组中的一个唯一三维索引,可以通过 \(gl\_WorkGroupID * gl\_WorkGroupSize + gl\_LocalInvocationID\) 计算而来。in uint gl_LocalInvocationIndex: 表示当前线程在全局工作组中的一个扁平化的一维索引。可以通过以下表达式计算得出: \[\begin{aligned} gl\_WorkGroupSize.x \times gl\_LocalInvocationID.x + & \\ gl\_WorkGroupSize.y \times gl\_LocalInvocationID.y + & \\ gl\_WorkGroupSize.z \times gl\_LocalInvocationID.z & \end{aligned}\]
之前提到过,subgroup 就是硬件所能控制的最小线程束,因此它等价于 AMDGPU 的 wavefront。在 Navi3 上,wavefront 支持 wave32 和 wave64,因此查询 vulkan info 可以看到其 subgroup size 的定义为:
minSubgroupSize = 32
maxSubgroupSize = 64在程序中,我们可以使用以下相关变量:
in uint gl_SubgroupSize: 总是和 API 设置的 subgroup size 相同,也就是说,用户可以在 AMDGPU 上自行选择 subgroup 的大小。in uint gl_SubgroupInvocationID: 在一个 subgroup 内线程的 ID。范围总是在 \(\left[0, subgroupSize\right)\)。in uint gl_NumSubgroups: 在一个 workgroup 内有多少个 subgroup。这个值取决于 workgroup 的大小,且最少是 1。简单地计算方式为 \(\lfloor (workgroupSize+subgroupSize-1)/subgroupSize \rfloor\)。in uint gl_SubgroupID: workgroup 内每个 subgroup 的唯一编号。范围 \(\left[0,numSubgroups\right)\)。
线程标识的实现
在 HW 启动程序时会初始化一些基本状态:
| 寄存器 | 值 |
|---|---|
| s0~s15 | User data |
| then | WorkGroupID.x |
| then | WorkGroupID.y |
| then | WorkGroupID.z |
| then | MultiDispatchInfo |
| v0 | LocalInvocationIndex.x (10bit) |
另外在计算 SubgroupInvocationID 时通常使用该组指令:
; EXEC = 0xFFFFFFFF / 0xFFFFFFFFFFFFFFFF
v_mbcnt_lo_u32_b32 v0, -1, 0
v_mbcnt_hi_u32_b32 v0, -1, v0 ; if SubgroupSize is 64Subgroup 操作
- Vulkan Subgroup Tutorial
- Vulkan Subgroup Explained
- 现代图形 API 的 Wave Intrinsics、Subgroup 以及 SIMD-group
内存模型
内存模型描述了线程通过内存的交互以及它们对数据的共享使用,因此这在 CS 中极为重要,同时也是现代通用编程语言的多线程基础。并以此衍生出了 Memory ordering、Memory barrier、Atomic 等概念。
推荐阅读:
- Memory Models 系列文章
- std::memory_order
- LLVM Language Reference Manual - Memory Model for Concurrent Operations
- LLVM – LLVM Atomic Instructions and Concurrency Guide
IEEE 754
浮点数的表示
以单精度浮点数 (float) 为例,其以 1 bit 符号位 (S),8 bit 指数位 (E) 以及 23 bit 尾数位 (F) 构成。
| 类别 | 符号位 | 指数位 | 实际表示的指数 | 尾数位 | 数值 | 二进制表示 |
|---|---|---|---|---|---|---|
| 零 | 0 | 0x00 | -127 | 0x000000 | 0.0 | 0x00000000 |
| 负零 | 1 | 0x00 | -127 | 0x000000 | -0.0 | 0x80000000 |
| 一 | 0 | 0x7F | 0 | 0x000000 | 1.0 | 0x3F800000 |
| 负一 | 1 | 0x7F | 0 | 0x000000 | -1.0 | 0xBF800000 |
| Normal | * | 0x01 ~ 0xFE | ||||
| 最小的 Normal | * | 0x01 | -126 | 0x000000 | \(2^{1-127}\) | 0x00800000 |
| 最大的 Normal | * | 0xFE | 127 | 0x7FFFFF | \(\num{3.4e38}\) | 0x7F7FFFFF |
| Denormal | * | 0x00 | -126 | 非零 | ||
| 最小的 Denormal | * | 0x00 | -126 | 0x000001 | \(\num{1.4e-45}\) | 0x00000001 |
| 最大的 Denormal | * | 0x00 | -126 | 0x7FFFFF | \(\num{1.18e-38}\) | 0x007FFFFF |
| 正无穷 | 0 | 0xFF | 128 | 0x000000 | \(+\infty\) | 0x7F800000 |
| 负无穷 | 1 | 0xFF | 128 | 0x000000 | \(-\infty\) | 0xFF800000 |
| NaN | * | 0xFF | 128 | 非零 | NaN | |
| signaling NaN | * | 0xFF | 128 | 0x000001 ~ 0x3FFFFF | 0x7FBFFFFF | |
| quiet NaN | * | 0xFF | 128 | 0x400000 ~ 0x7FFFFF | 0x7FFFFFFF |
精度
浮点数的精度通常使用 ULP (Unit in the last place) 表示,简单地说就是浮点数在保留指数位时,其最低有效位为 1 时所表示的值。比如说 1.0 (0x3f800000),其 ULP(1.0) 表示为 float(0x3f800001)-1.0。
比如说 Navi31XTX 上,V_ADD_F32 的精度是 0.5 ULP,V_EXP_F32 的精度是 1.0 ULP。
Float Control
Compiler
简介
llvm
├── ADT
├── Analysis
├── CodeGen
├── IR
├── MC
├── Target
│ ├── AArch64
│ ├── AMDGPU
│ ├── RISCV
│ └── X86
└── Transforms
├── Coroutines
├── InstCombine
├── Instrumentation
├── Scalar
└── Vectorize订阅社区消息: Preferences -> Tracking -> Watched (`IR&Optimizations`, `AMDGPU`)
LLVM IR 基础结构
Module -> Function -> ControlFlowGraph -> BasicBlock -> Instruction

BB:
- BB 内的所有指令顺序执行
- BB 最后一条指令一定是 Terminator Intruction,表示 BB 之间的关系
- phi 只能出现在 BB 的起始位置,表示 BB 之间的数据流动
Function:
- 一定只有一个 `.exit` BB
- 优化在 Function 上执行
CFG:
- CFG 是 Function 内 BB 之间的关系
- Dominator Tree
- Loop: LCSSA

优化
Analysis + Transform